
A Gentle Introduction of Evaluation Techniques for LLM-Applications
Integrating Large Language Models (LLMs) into production workflows presents several challenges, including hallucinations, where models generate incorrect or nonsensical outputs, and rate-limits imposed by providers that can hinder real-time applications. Additionally, choosing the right LLM involves balancing cost and performance, with high-performance models offering advanced capabilities at a significant computational cost.
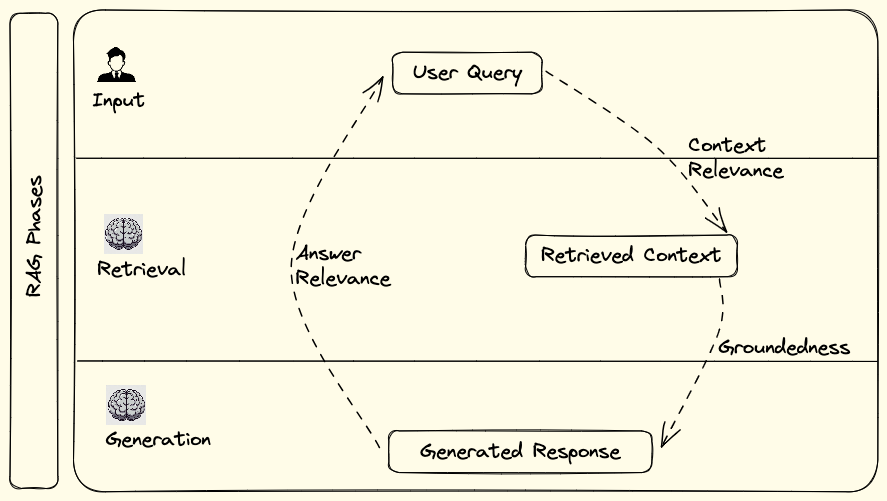
Evaluation Process of Agentic-RAG
A robust evaluation system is critical for ensuring the reliability of LLM-powered applications. Key components of this system include high-quality datasets, various types of evaluators (human, heuristic, and LLM-based), and thorough assessment methods like comparison and scoring. These evaluations are particularly important in Retrieval-Augmented Generation (RAG) systems, where context relevance, groundedness, and answer relevance must be carefully measured.
For a detailed exploration of these challenges and evaluation methods, read this original article.